リコーのAI技術
はたらく人の創造力を支え、
ワークプレイスを変えるサービスを
提供します。
はたらく人のさまざまなシーンに寄り添い、
質の高い支援を届けるために、
リコーはそれぞれのワークプレイスの
課題を深く理解し、
最適なAIを開発して使いこなすことで、
最適な解を見つけ出し、
はたらく人へ価値を提供していきます。
リコーの提供するAI技術






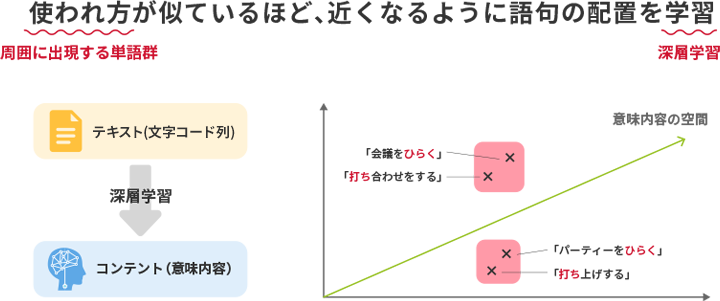
自然言語とは、人が話したり書いたりする言葉です。その言葉の中には曖昧な表現や意味が含まれるため、機械的に処理することは困難でした。
リコーは独自の技術により、その言葉(自然言語)に存在する曖昧性やゆらぎを、
文章の中で離れた単語間の関係までを把握し「文脈」を考慮した処理を可能にしました。
「自然文の質問への回答」や「文書の要約」といった処理を人間並みの精度で実行でき、学習も容易にできるようになります。
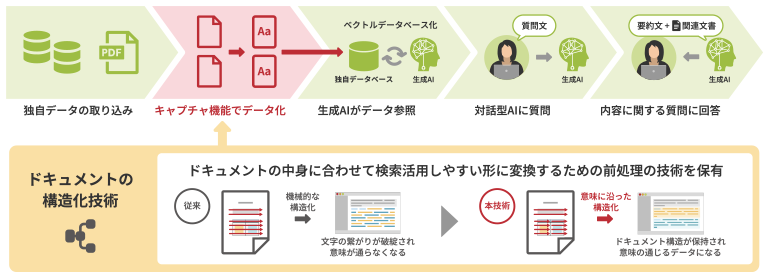
RAG(検索拡張生成)は、LLM(大規模言語モデル)による結果を最適化するプロセスです。LLMの膨大な事前学習データだけでなく、企業固有のデータ等もベクトル化しておくことで、入力(クエリ)のベクトルと照合して最適な結果を導き出します。モデルを再学習することなく、特定の分野や組織の内部ナレッジに拡張できるので、より正確でカスタマイズされた独自の生成AIシステムにすることができます。
リコーは、長年お客様の業務やデータに関わってきたことで、ドキュメント分析に対応できる豊富な知識と経験を有しており、ドキュメントの構造化技術で最適なAIインテグレーションを実現します。
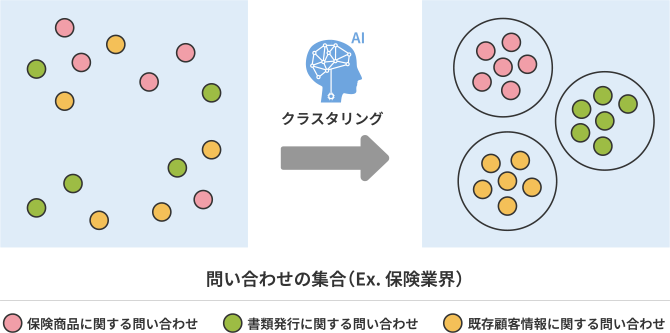
クラスタリングとは、データ間の類似度にもとづいて、データをグループ分けする手法です。
事前に用意された教師データを学習することなく、データを元にテキストの意味の近さや特徴を学習してグループ分けするので、内容ごとの分布を可視化したり、二種類のデータ群の分布を重ねて可視化するなどができます。
クラスタリングによってできた、似たもの同士が集まったグループのことをクラスタと呼びます。
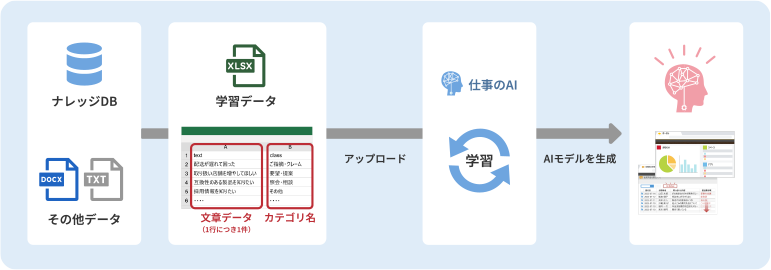
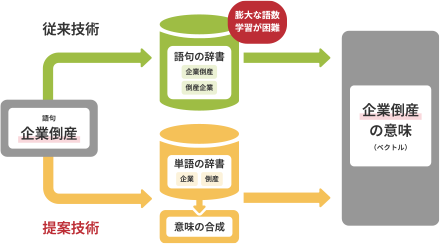
AIを企業が業務で使うには、企業や業界固有の用語などをAIに学習させる必要があります。そのためにはデータの準備や学習させるための時間、コスト、専門知識が課題となっていました。
リコーは、テキスト分類において、これらの作業をお客様自身で容易に行えるツールを開発しました。
特別な知識がなくても、テキストとその分類カテゴリーをExcelデータで作成してアップロードするだけで、企業独自のテキスト分類用AIモデルを作成することができるようになります。
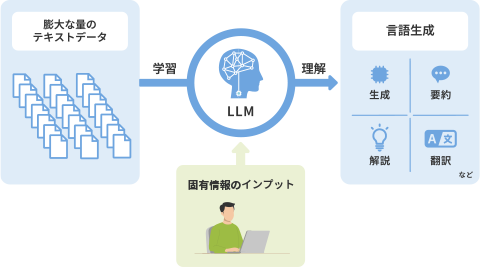
LLM(大規模言語モデル:Large Language Models)は、大量のデータを学習し、主にテキストでの文章生成や要約、質問応答などを行う生成AIの中核となる技術です。
リコーは、日本企業の業務で安心して活用できる生成AIを実現するため、独自のLLMおよびLMM(大規模マルチモーダルモデル)を開発しています。日本語に最適化したトークナイザーや、日本企業に特有の図表・画像を含む複雑な文書を読み取るマルチモーダル技術を強みとし、実運用を見据えた開発を行っています。
セキュリティ確保のため、オンプレミス環境での導入を前提にした小型・高性能化と低コスト運用を両立し、お客様固有のデータや業務に合わせた個別カスタマイズ(プライベート化)を可能にしています。
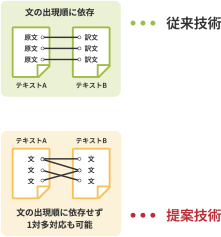
「ディープアライメント」は、構成の違う2つの文書の内容を比較し、文や段落を自動的に対応させて重複や差異を明確にできるAIを活用したリコー独自の自然言語処理技術です。
複数の単語から語句を合成することで文の意味を把握。比較する2つの文書間で、類似した内容を含む文や段落を出現順に関わらず自動的に対応づけします。
ドキュメント内のテキストを読み取ることができるリコー独自LLMに加えて表や図表を読み取ることができる“Large Multimodal Model(LMM)”。
お客様のドキュメント特性に合わせたチューニングを行い、よりお客様のことを理解したリコー独自のLMMをご提供します。

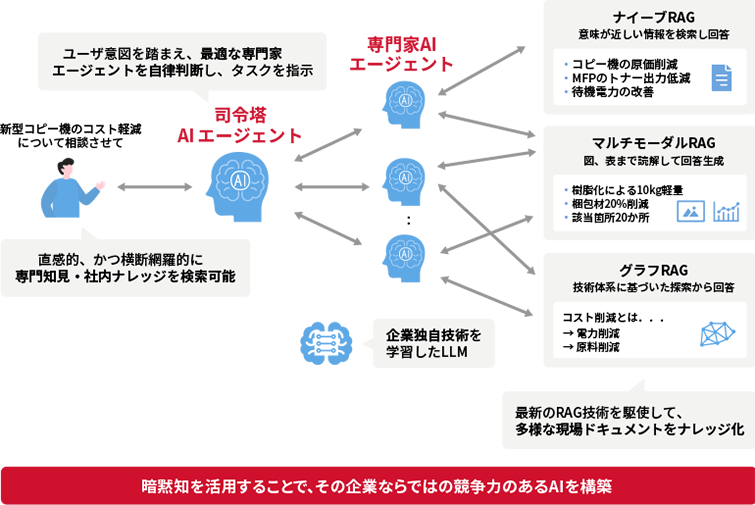
文書の内容に合わせて、ナイーブRAG、マルチモーダルRAG、グラフRAG、といった技術を組み合わせた専門家AIエージェントを作ることができます。
司令塔AIエージェントが作った専門家AIエージェントを統括して、動くことで、ユーザーは司令塔AIエージェントに対して質問するだけで、自動的に最適なナレッジを探し出すことが可能になります。
人材開発
お客様の課題解決につながる
新鮮なAIの応用を提案するために、
社員みんながお客様にAIの提案ができる
AIネイティブな会社を目指します。
リコーグループ全体でAI人材を育成しています。各サービス開発のAI担当者が実務にAIを組み込み、必要に応じてAI専門組織が支援を行います。社内実践として、独自のアルゴリズムを用いた部品の外観検査の実施や、クラウドOCRやチャットボットの業務での活用などにより、業務効率化と品質向上に取り組んでいます。それらの経験を生かしてお客様の課題をAIで解決できる体制を築いていきます。


